

Veri gazeteciliğinin öneminden, bileşenlerinden ve örneklerinden sıklıkla bahsetmeye çalışıyorum, bunların yanına veri muhabirlerinin deneyimlerini de eklemenin uygun olacağını düşündüm. Kaiser Health News için The Other COVID Risks: How Race, Income, ZIP Code Influence Who Lives Or Dies hikâyesini hazırlayan Hannah Recht, Source‘ta yayımladığı yazıda da hikâyenin oluşum sürecini aktarmış. Böyle deneyimlerin henüz Türkiye’de emekleme sürecinde olan bu pratiğin gelişmesine katkı sağlayacağını umut ediyorum. Bu hevesle ilgili yazıyı çevirdim:
ABD’deki sağlık eşitsizlikleri iyi belgelenmiştir. İnme, diyabet, gebeliğe bağlı ölümler neredeyse hepsi, gelirler hesaba dâhil edildiğinde bile en çok azınlıkları etkiledi. Yapısal ırkçılık ve sağlığın sosyal belirleyicileri; tıbbi bakımdan sigorta erişimine, hastane yatağının kullanılabilirliğinden ellerinizi 20 saniye boyunca yıkayabilmeye kadar sağlık hizmetlerinin her yönünü etkiler. Bu hikâyeyi anlatmak, Covid-19 vaka oranlarının ve ölümlerinin ABD’deki azınlık topluluklarını neden orantısız olarak etkilediğini açıklamanın önemli bir parçasını oluşturmaktadır. Ülke genelinde yeni Covid-19 sıcak noktaları ortaya çıktığı sürece ve etnik kökene göre veri yayımlanmaya başladıkça, Kaiser Health News’deki ekibim hastalığın neden Siyah, Hispanik ve Kızılderili topluluklarını bu kadar yoğun bir şekilde etkilediğini haberleştirme ihtiyacı gördü. Haberde yer alacak bölgeleri belirlemek ve kişi başına düşen Covid-19 vakalarının giderek artan sayıda olduğu savunmasız toplulukları tanımlamak için birden fazla veri kaynağı kullanarak büyük bir ulusal veri setini bir araya getirdim.
Bulduğumuz Hikâye
Derlenmiş verilerimiz, ulusal spot ışığı dışında kalan birçok topluluğun salgınla boğuştuğunu ve virüsün yayılmasını durdurmak için önlerinde bir dizi engelin bulunduğunu ortaya koydu. CDC (Hastalık Kontrol ve Korunma Merkezleri) eski direktörü Dr. Thomas Frieden’in hikâyemizde dediği gibi, “Salgınların çoğu; yoksul, haklarından mahrum bırakılmış ve altta yatan sağlık sorunları olanları hedef alan güdümlü füzelerdir.” Bizim çalışmamız, hastalıkta yükselen oranlara sahip olan ve daha da şiddetli salgınlar için yüksek risk altında bulunan üç bölgeye odaklandı: Mississippi, Navajo Nation ve Tennessee eyâletinde yer alan Memphis. Tümü yoksulluk, altyapı sorunları ve altta yatan sağlık durumlarının yüksek oranları da dâhil olmak üzere virüsü kontrol etmeyi zorlaştıran ciddi zorluklarla karşı karşıya. Bu bölgeleri tanımlamak için Covid-19 verilerini demografik bilgiler, gelir, yoksulluk, sağlık sigortası, hastane erişimi ve sosyal güvenlik açığı ile birleştiren bir veri seti oluşturdum. New York ve New Orleans gibi çok yüksek vaka oranlarına sahip alanları sıkça ele alındıkları için atladık.
Verileri Nasıl Analiz Edebilirsiniz?
Hikâyemizde sigortasız ve yoksulluk oranları, medyan ev halkı geliri, yaşlıların yüzdesi ve ırk / etnik köken dökümü içeren ilçe düzeyinde bir veri seti yayımladık. Ayrıca yayımlanma sırasında 100.000’de Covid-19 vakaları, ölümleri ve vaka oranlarını da ele aldık. Araştırılacak bir diğer önemli kaynak, toplulukların salgınlar ve felaketlerle başa çıkma yeteneklerini değerlendiren CDC’nin Sosyal Güvenlik Açığı Endeksidir. CDC, endeksin ulusal ve eyalet temelli olmak üzere iki versiyonunu yayımlamaktadır. Eyaletlere dayalı versiyon, bir eyalet içindeki alanları birbirine karşı sıralar; yalnızca bir eyalette haberleştirme yapıyorsanız bunu kullanmak istersiniz. İki versiyonu da sayım bölgeleri ya da il düzeyinde indirilebilir. Şimdi, bu verileri analiz etmeye başlayalım: KHN’de yayımlanan ve hikâyemizde yer alan ilçe bazında veri setini, tarifi takip edebilmek için indirmelisiniz. Zip dosyasındaki kullanım koşullarını kabul ettiğinizden ve notları okuduğunuzdan emin olun. Covid-19 vakaları her gün değiştiği için, ilçe dosyasını New York Times’tan indirerek güncel verileri alın. us-counties.csv dosyasını tıklayın ve indirme düğmesine basın. (Tarayıcınız csv’yi yeni bir sekmede açarsa, dosyanın yerel bir kopyasını isterseniz indirme düğmesinde sağa tıklayıp “farklı kaydet” i seçebilirsiniz). Coğrafi istisnalar bölümünü inceleyin. Big Local News haritası Times’tan güncel verileri çekmektedir. Analiz yapmak zorunda kalmadan oranlara hızlıca bakmak için de kullanabilirsiniz. Bölgenizi belirleyerek Endeksi indirin. Öncelikle 2018 belgelerini seçin ve ardından verileri belirleyin. Tek bir eyalette haberleştirme yapıyorsanız, “geography” açılır menüsünden eyalet adını seçin. Birden çok eyaleti hedefliyorsanız “United States”i seçin. Coğrafya türü için ilçeleri, dosya türü için CSV’yi seçin ve “Go”yu tıklayın. NOT: Daha geniş bir çalışma için “national, county-level” sürümü kullandık, ancak yerel muhabirler “census tract state-based” ölçümlerine bakmak isteyebilir. Seçtiğiniz analiz programını açın. İki seçenek üzerinden yöntemlerimiz hazır: Google E-Tablolar ve R. İlgilendiğiniz program R ise onun talimatlarına atlayın. Google E-Tablolar’ı kullanarak takip etmek isterseniz, bu tarif için özel olarak oluşturduğumuz bu dosyayı açın. (Ç.N. Ben çalışmalarımda R kullanmayı tercih etsem de E-Tablolar ile aktarılan yönlendirmeleri de çeviriye ekliyorum.)
Google E-Tablolar Talimatları
Sayfayı düzenleyebilmek için bir kopyasını oluşturmanız gerekiyor. Dosya>Kopyasını Oluştur’a giderek işlemi gerçekleştirebilirsiniz. Sekmelerden görülebileceği üzere KHN veri setinde Data, Term of Use ve Methodology and Data Sources bölümleri bulunuyor. Yakında bu veriler yerine güncel verileri ekleyeceğimiz için sayfadaki orijinal Covid-19 vakalarını kaldırdığımızı unutmayın. Daha sonra yapılacak işlemlerin kolaylaşması için de FIPS kodlarının (Ç.N. İlçelere özgü verilen kodlar, 5 haneli olması gerekirken 4 haneli olarak veri setinde yer alıyor) başlarında olması gereken “0”ların bulunmadığını belirtelim. Endekste eğer tek bölge seçtiyseniz ve yalnızca bu bölge üzerinden çalışmak isterseniz bu veri setinde işinize yaramayacak bölgeleri silmeniz faydalı olacaktır. 3 ayrı veri seti üzerinde çalışacağımızı düşünürsek süreci kolaylaştıracaktır. (Ç.N. Ben çalışmayı denemek için her veri setinin en altında yer alan Wyoming eyaletinin ilçelerini alarak veri setini daralttım) İndirdiğimiz iki ek veri setini Dosya > İçe Aktar sekmelerinden seçin ardından Endeks verileri için Yükle’yi tıklayın. Google E-Tablolar size dosyayı nasıl içe aktarmak istediğinizi soracaktır. İçe Aktarma konumunu yeni sayfa oluştur olarak belirleyerek veri setini tek başına ele alın. İçe Aktar’a tıkladığınızda, csv dosyasıyla aynı sayfa adına sahip yeni bir sayfa oluşacaktır. Endeks verilerinde iki sütun arayın: Birincisi ilçeleri tanımlayan FIPS sütunu ikincisi ise RPL_THEMES toplam Sosyal Güvenlik Açığı Endeks değişkeni. (RPL_THEMES sütununu bulmak için RPL_THEME1 – RPL_THEME4 arasında ilerlemeye devam edin hemen ardından göreceksiniz; gerçekten orada!) Bunları sola, birinci ve ikinci sütunlarınız olacak şekilde sürükleyin. Ardından, sütun başlığını sağ tıklayıp seçeneğini belirleyerek bu sayfayı FIPS sütununa göre sıralayın sayfayı A -> Z düzeninde sırala. Bunu yapmak sizi daha sonra büyük bir baş ağrısından kurtaracaktır. Veri setimize “data” geri dönerek fips_county ögesine sağa 1 ekle diyerek sağında yeni bir sütun oluşturun. Bu sütunu svi olarak adlandırın. Bir sonraki boş hücrede (B2 olmalı), aşağıdaki formülü yapıştırın. Her iki yerde de YOUR_SVI_SHEET_NAME yerine kendi SVI sayfanızın adını yazın: =INDEX(YOUR_SVI_SHEET_NAME!B:B, MATCH(A2, YOUR_SVI_SHEET_NAME!A:A, 0)) (Ç.N. Verilerimizi eklediğimizde Google e-Tabloları türkçe kullanıyorsak formülümüz aşağıdaki gibi olacaktır: =İNDİS(svi!B:B, KAÇINCI(A2, svi!A:A, 0)) Bu formülün işlevi veri setinde yer alan Fips kodları ile eşleşmiş sütunu diğer veri setine aktarırken eşleşmenin bozulmadan tamamlanmasını sağlamaktır. Yeni oluşturduğunuz hücreyi (B2) seçip kutunun sağ alt köşesindeki küçük, mavi kareyi iki kez tıklayarak bu formülü tüm sütuna aktarabilirsiniz. Kutuyu aşağıya doğru çektiğinizde de hücreler dolacaktır. Bu aşamada da NYT’nin güncel COVID-19 verilerini yükleyeceğiz. Verileri içe aktarma aşaması en son yaptığımızla aynı olacaktır. Dosya’dan içe aktar’ı seçelim. Daha sonra önceden indirdiğimiz us-counties.csv dosyasını seçip yükleyelim. İçe Aktarma konumunu yeni sayfa oluştur olarak belirleyerek veri setini tek başına ele alalım. İçe Aktar’a tıkladığımızda, csv dosyasıyla aynı sayfa adına sahip yeni bir sayfa oluşacaktır. Dosyamızda “us-counties.csv” yalnızca son günden itibaren olan güncel verileri istiyoruz, bu yüzden önce bunları en üste doğru sıralayacağız. Tarih sütununa sağ tıklayın ve en son tarihli satırları en üste getirecek Z -> A düzeninde sırala’yı seçin. Şimdi, KHN veri setine geri dönersek, INDEX-MATCH kullanarak iki veri setini önceki adımlarda yaptığımız gibi birleştireceğiz. A sütununa tıklayıp sağa 1 ekle’yi seçip fips_county öğesinin sağında iki yeni sütun oluşturun. Boş sütundaki ilk hücreyi covid_cases ve ikincisini covid_deaths olarak etiketleyin. B2’de daha önce yaptığımız gibi, en son vaka verilerini getirecek olan formülü yapıştırın: =INDEX(‘us-counties’!E:E, MATCH(A2,’us-counties’!D$1:D$2887, 0)) (Ç.N. Dosya ismini değiştirdim türkçe sürümde yer alan formül bu şekilde: =İNDİS(nyt!E:E, KAÇINCI(A2,nyt!D$1:D$2887, 0)) Bu formülle veri setimizdeki 2887. hücreye atıfta bulunuyoruz, çünkü bu satır son tarihin son veri satırı olarak yer almaktadır. Durumun böyle olup olmadığını kontrol edin. Değilse, formülde yer alan 2887. hücreyi bulduğunuz tarihin son veri satırı olarak güncelleyin. Yeni oluşturduğunuz hücreyi (B2) seçip tüm sütuna uygulamak için küçük, mavi kutuyu çift tıklayarak formülü tüm sütuna uygulayın. New York Times veri setinde, bildirilen vakaların olmadığı için “N / A” içeren bazı hücreler görebilirsiniz. Aşağıdaki formülü C2’de güncel can kaybı verilerini getirmesi için kullanın: =INDEX(‘us-counties’!F:F, MATCH(A2,’us-counties’!D$1:D$2887, 0)) (Daha önce 2887 hücresini değiştirdiyseniz, burada da değiştirmeniz gerekir.) Yeni oluşturduğunuz hücreyi (C2) seçin ve tüm sütuna uygulamak için küçük, mavi kutuyu tekrar çift tıklayın. Tebrikler, üç veri setini başarıyla birleştirdiniz! Son adımda her ilçede 100.000 kişiden kaç kişinin Covid-19 vakasına yakalandığını hesaplamak için kendi sütunumuzu oluşturacağız. Bu kez covid_cases sütununun sağına yeni bir sütun ekleyin. Covid_cases_rate olarak adlandırın. Bu sayıyı hesaplamak için şunları yapacağız: (vakalar / nüfus) * 100000, yani kullanılacak formül: =(B2/L2)*100000. Eğer sütunlarınızı bu kılavuzla tam olarak aynı yere koymadıysanız bunu da uygulayabilirsiniz: =(cases column/population column)*100000. Yine, formülü tüm sütuna uygulamak için yeni oluşturduğunuz hücreyi seçin ve küçük, mavi kutuyu çift tıklayın. Şimdi her ilçe için 100.000 kişi başına Covid-19 vaka oranına sahip olmanız gerekiyor. Bunu nasıl anlamlandırdığımızı doğrudan görmek isterseniz R talimatları bölümünü atlayabilirsiniz.
R Talimatları
Veri setlerimizi kısa bir programla birleştireceğiz. Öncelikle atacağımız her adımı anlatacağım ve sonra bunu R’da nasıl yapacağınızı göstereceğim: İlk adımda, indirdiğimiz üç veri setini R’a yükleyeceğiz. İşleri kolaylaştırmak için, bu üç veri setinin R çalışma klasörünüzde bulunduğundan emin olun: a. KHN_County_vulnerability_data.csv b. CDC’den endeks verileri c. NYT’den Covid-19 verileri Bu üç veri setinin hepsini birlikte yükleyeceğiz. a. FIPS kodlarını kullanarak, Endeks verilerini KHN verileri ile birleştirin. Endeks verilerinden, ‘RPL_THEMES’ adlı Sosyal Güvenlik Açığı değişkenini istiyoruz. b. Covid-19 vakalarının en güncel verilerini alabilmek için tarih sütununa filtre uygulayabilir ya da sıralamyı değiştirebiliriz. c. Birleşen Endeks / KHN veri setinde covid_cases, covid_deaths ve covid_cases_rate başlıklarını, güncel olmadığı için kaldıracağız. d. Birleşen Endeks / KHN verilerimize filtrelediğimiz güncel Covid-19 vaka verilerini ekliyoruz. e. Veriler birleştirildikten sonra 100.000 kişi başına düşen vaka oranlarını kolayca hesaplayabiliriz: (vakalar / nüfus) * 100000. Artık ilgilendiğiniz bölgede; hangi eyaletlerin kişi başına daha fazla sayıda vakaya ve daha fazla sosyal güvenlik açığına sahip olduğunu görmek için verilere bakabilirsiniz. Ayrıca, nüfusun ırksal sorunlarını, gelir durumunu ve sigortasız oranlarını hemen görebilirsiniz. Şimdi, tüm bu adımları kendiniz atmak için, tüm kod blogunu yeni bir R komut dosyasına kopyalayın ve R’da çalıştırın. İsterseniz her bölümü birer birer çalıştırabilirsiniz, aynı zamanda birlikte de çalışacaktır!
#Dplyr kütüphanesini yükleyip çalıştıralım
#İlk defa indirecekseniz gerekli kod: install.packages("dplyr")
library(dplyr)
#KHN verilerini yükleme
county_dt <- read.csv("KHN_County_vulnerability_data.csv", stringsAsFactors = F, colClasses = c("fips_county" = "character", "fips_state" = "character", "cz_code" = "character"))
#Endeks verilerini yükleme - Eyalet tabanlı bir dosya indirdiyseniz farklı bir dosya adınız olabilir
svi <- read.csv("SVI2018_US_COUNTY.csv", stringsAsFactors = F, colClasses = c("FIPS" = "character"))
#New York Times'ın güncel Kovid-19 vaka verilerini yükleme
İndirdiğiniz seti ya da burada olduğu gibi veri setini doğrudan github'dan yükleyebilirsiniz:
covid_full <- read.csv("https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv", stringsAsFactors = F, colClasses = c("fips" = "character"))
#Endeks verilerini KHN veri setine yükleme
svi_min <- svi %>% select(fips_county = FIPS, svi = RPL_THEMES)
county_dt <- left_join(county_dt, svi_min, by = "fips_county")
#Birleştirmeden önce verileri temizleme
covid_full <- covid_full %>% mutate(date = as.Date(date)) %>%
rename(fips_county = fips, covid_cases = cases, covid_deaths = deaths)
#En güncel verileri ve gerekli sütunları seçme
covid_latest <- covid_full %>% filter(date == max(date)) %>%
select(fips_county, covid_cases, covid_deaths)
#Eski verileri silerek güncel vaka durumlarını yükleme
county_dt <- county_dt %>% select(-starts_with("covid_"))
county_dt <- left_join(county_dt, covid_latest, by = "fips_county")
#Her bölge için 100.000 kişiye düşen vaka sayısını hesaplama
county_dt <- county_dt %>% mutate(covid_cases_rate = (covid_cases/population) * 100000)
#Bir eyaleti seçin, örneğin Texas. 30 Nisan verileri ile Harris County, TX'te covid_cases = 6161 ve covid_cases_rate = 130.7 durumu görüldü. Güncellenen vakalar farklı oranlar ortaya çıkarabilir.
#(Ç.N. 20 Temmuz'da bu yazıyı çevirdiğim sıralarda Teksas'ta güncel vaka durumu şöyle: covid_cases = 54806, covid_deaths = 533, covid_cases_rate = 1162.78848)
texas <- county_dt %>% filter(state_code == "TX")
Veriyi Analiz Etme
KHN, CDC ve NYT veri setlerimiz bir araya geldiğinde zaten güçlü haberleştirme araçlarına sahip olacağız. Oluşturacağımız yeni veri sütunları şunlardır:
covid_cases: Ham vaka sayıları.
covid_cases_rate: 100.000 kişi başına düşen oran bizlere, salgının irili ufaklı bölgelerde yayılımını karşılaştırmanın bir yolunu sunar.
covid_deaths: Ham vefat sayısı.
svi: CDC'den alınan endeks verileri 0 ile 1 arasında değişmekte ve 1 değerine yakınlık salgınlarına ve afetlere karşı savunmasızlığı göstermektedir.
Şimdi ilgilendiğiniz bölgedeki Kovid-19 vakalarının başka bir önemli boyutunu, ırksal ve / veya etnik etkilerini arayacağız. İlgilendiğiniz eyalet, şehir ya da ilçelerde Kovid-19 verilerini ırk ve / veya etnik kökene göre yayınlanıp yayınlamadıklarını kontrol edin. Varsa, bunları bölgedeki toplam nüfus verileri ile karşılaştırabilirsiniz. Irk ve etnik kökene göre Kovid-19 verileriniz yok ise yine de bu hikâyeyi tamamlayabilirsiniz. (Yerel yetkililerden verileri talep ettiğinizde paylaşmaları gerekir.) Çalışmamızda öncelikle Kovid-19 vaka oranlarına ve tartıştığımız diğer yoksulluk, hastaneye erişim, sosyal güvenlik açığı, demografi ve altyapı dâhil olmak üzere verilere odaklanacağımız bölgeleri seçtik. Vakaları ve ölümleri anlamlandırmak için biz etnik kökene dayalı verileri kullandık ama hikâyeyi onsuz da anlatırdık. Çalışmamızda Tennessee eyaletine bağlı Mississippi ve Shelby County için ırk ve etnik köken verileri sunduk, her ikisi de bölgenin siyah sakinleri arasında büyük bir Kovid-19 yayılımını gösterdi.

New York gibi bazı eyaletler ırkları ve İspanyol etnik kökenlerini verilerinde birlikte tutarken Tennessee gibi diğerleri ayrı tutuyor. Kayıtların çoğu ırk ve etnisiteyi ayrı değişkenler olarak tutar. İlgilendiğiniz bölgede kayıtlar birlikteyse doğrudan bununla nasıl başa çıkacağımızı açıkladığımız Senaryo 2’ye atlayın.
Senaryo 1: Irk ve Etnik Kökeni Ayırma
İlgilendiğiniz bölge ırk ve etnik kökenleri ayrı olarak paylaşıyorsa ırk verilerini tablo B02001’de, İspanyol veya Latin etnik köken verilerini ise B03003’te bulabilirsiniz. (Bu verileri data.census.gov adresinden de alabilirsiniz, ancak censusreporter.org’un kullanımını çok daha kolay buluyorum! Ya da program kullanıyorsanız Census Bureau API’lerini deneyin.) Örneğin: Tennessee eyaleti İspanyol etnik kökenin verilerini ayrı ırkları ayrı olarak paylaşmaktadır. 30 Nisan verilerinde vakaların %27’si henüz belirlenemeyen (pending) ırkları içermekteydi. Karşılaştırmalı çalışmalarda bunları çıkarmamız gerecek. Bu yüzden bilinen ırk verilerini kullandık.

Excel, Google E-Tablolar ya da sevdiğiniz bir istatistik programına, kesin olmayan verileri çıkararak ırklara göre vaka sayılarını girin. Ardından, her vaka sayısını yüzde üzerinden hesaplayarak sütun yapın. Bu sayılar %100’ü sağlayacak şekilde düzenlenmelidir. Aşağıdaki A, B ve C sütunlarına bakın:
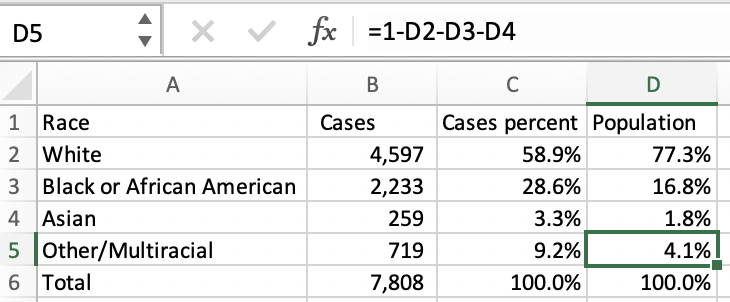
Daha sonra ırka göre Kovid-19 vaka yüzdelerini ACS verilerini kullanarak kıyaslayabiliriz. (İlgilendiğiniz bölgeye ait verileri görüntülemek için soldaki “Add a geography” alanına ilçeyi, şehri veya eyalet adını girin.) Bu verileri de Excel’e yükleyin, biz D sütununa “Population” olarak ekledik. Ne yazık ki Tennessee, çoğu eyalet gibi Kızılderili, Alaska Yerlileri, Hawaii Yerlileri ve Diğer Pasifik Adalı popülasyonları için Kovid-19 verilerini bildirmez. Eksik grupları “Diğer” kategorisi içerisinde alarak %100’e tamamlayabiliriz. Kovid-19 vaka dağılımı eyaletin nüfusunu yansıtıyorsa, bu yüzde sütunlarının kabaca aynı görünmesini beklersiniz. Siyahi sakinler eyalet nüfusunun sadece %16,8’ini fakat vakaların %28,6’sını oluşturduğunu görebilirsiniz. Irka göre ölüm hesaplamalarını benzer bir şekilde yapabilirsin. Şimdi bu işlemi İspanyol etnik kökenine yönelik B03003’ü kullanarak ayrı bir sekmede tekrarlayacağız.

Tennessee’de eyalet nüfusunun sadece %5,5’i İspanyol ya da Latin ancak Kovid-19 vakası %13,3’üdür.
Senaryo 2: Karma Irk ve Etnik Köken Verileri
İlgilendiğiniz bölge karma ırk ve etnik köken verileri paylaşıyorsa bu tabloya başvurabilirsiniz, Bu veriler KHN ilçe düzeyinde veri setinde bulunmaktadır. New Jersey, Kovid-19 ölümlerini karma ırk ve etnik kökenle bildiriyor. (Alta doğru Dashbord’a inin ve demografik bilgileri tıklayın.)

Bu vaka sayılarını bir e-tabloya girerek her ırkın vakaları toplamının bölünmesiyle bir yüzde sütunu oluşturun. B03002’den aldığımız nüfus verilerini de yeni bir sütuna ekleyeceğiz.

ACS başlıklı tabloda Hispanik ya da Latinlerin ırksal olarak ayrıldığına dikkat edin. New Jersey verileri Hispanik ya da Latin kökenli olarak paylaştığından, ACS’nin popülasyon sayılarını da kullanacağız: %20.6. Ardından Hispanik olmayan Beyaz, Siyah ve Asyalı yüzdelerini ekleyin. New Jersey tüm gruplar için sayı bildirmez, bu nedenle Tennessee gibi verilerimizdeki grupları %100’den çıkararak tabloyu oluşturacağız.

New Jersey’de, Beyaz ve Asyalı Hispanik olmayan ve yalnızca Hispanik olan sakinlerin Kovid-19 ölümlerinin nüfus paylarından daha az olduğu görülmektedir. Siyah, Hispanik olmayan sakinler eyaletin sadece %12,8’ini oluştururken ölümlerin ise %19,7’sini oluşturuyor.
Hikâyenizi Nerede Arayacaksınız?
Verileri birkaç farklı yönde aramalısınız. Hangi ilçelerde en yüksek Kovid-19 vaka oranları var? En yüksek yoksulluk oranları nerede? En yüksek sosyal güvenlik sistemi açığı nerede? En çok etkilenen bölgelerin ve daha az oranlara sahip olan bölgelerin ırksal ve etnik yapısında farklılıklar var mı? İlçenize ve şehrinize göz atın Kovid-19 vaka oranlarını nasıl yayımlıyorlar. Bölgenizdeki hangi topluluklar en çok etkileniyor? Haberleştirilecek bazı alanlar bulduğunuzda, bu alanların neden bu kadar yüksek oranlara sahip olduğunu sorun. Aileler daha yoğun bölgelerde veya kalabalık konutlarda mı yaşıyor? Birden fazla nesil birlikte mi yaşıyor? Altta yatan hastalıkların oranları daha mı yüksek? Sakinlerin sağlık hizmetlerine kolay erişimi var mı? Evden sürdürülemeyen işleri daha mı yaygın? Bölgenizdeki halk sağlığı, konut ve eşitsizlikler konusunda sakinler, yerel kanaat önderleri ve uzmanlarla konuşun. Umarım bu veriler ve bilgiler yararlıdır ve yerel haberlerinizi okuyabiliriz.
Ç.N: Elbette ABD’nin demografik yapısı, ülke sorunları, veri şeffaflığı ve medya yapısı Türkiye’den çok farklı. Fakat bu çalışmayı çevirirken amacım bunlara odaklanmak değil gazetecinin veriye yaklaşım biçimini aktarmaktı. Sonuçta gazetecilik güdüsü ve habere yaklaşım, olaylara bakış açısı evrensel nitelik taşıyor. Tartışmasız veriye dair bilinç arttıkça verilerin miktarı da giderek artacaktır. Bu sebeple bu tarz deneyim paylaşımlarının önemli olduğu kanısındayım.









Bir yanıt yazın